Document Processing
Thousands of Documents. AI Reads Every One. Structured Data Lands in Your Systems.
Production-grade pipelines: layout-aware extraction, entity recognition, domain-specific NLP. Built for service companies handling high volumes of mixed document types.
What it solves
At small volume, manual entry works. At a thousand documents a week, it falls apart. Service operations that handle high-volume documents — claims processors, MGAs, medical assistance, professional services — hit a wall: hire more people to retype, or accept that documents pile up and the signal goes unused.
Off-the-shelf AI demos look impressive on a single document. In production, on thousands of documents with mixed formats, the wheels come off. Layouts vary. Vendors change templates every quarter. Medical, legal, and insurance documents have domain vocabulary general-purpose AI doesn't understand.
The result is a backlog that no one ever clears, and a reservoir of operational signal that lives in PDFs nobody will ever query.
How It Works
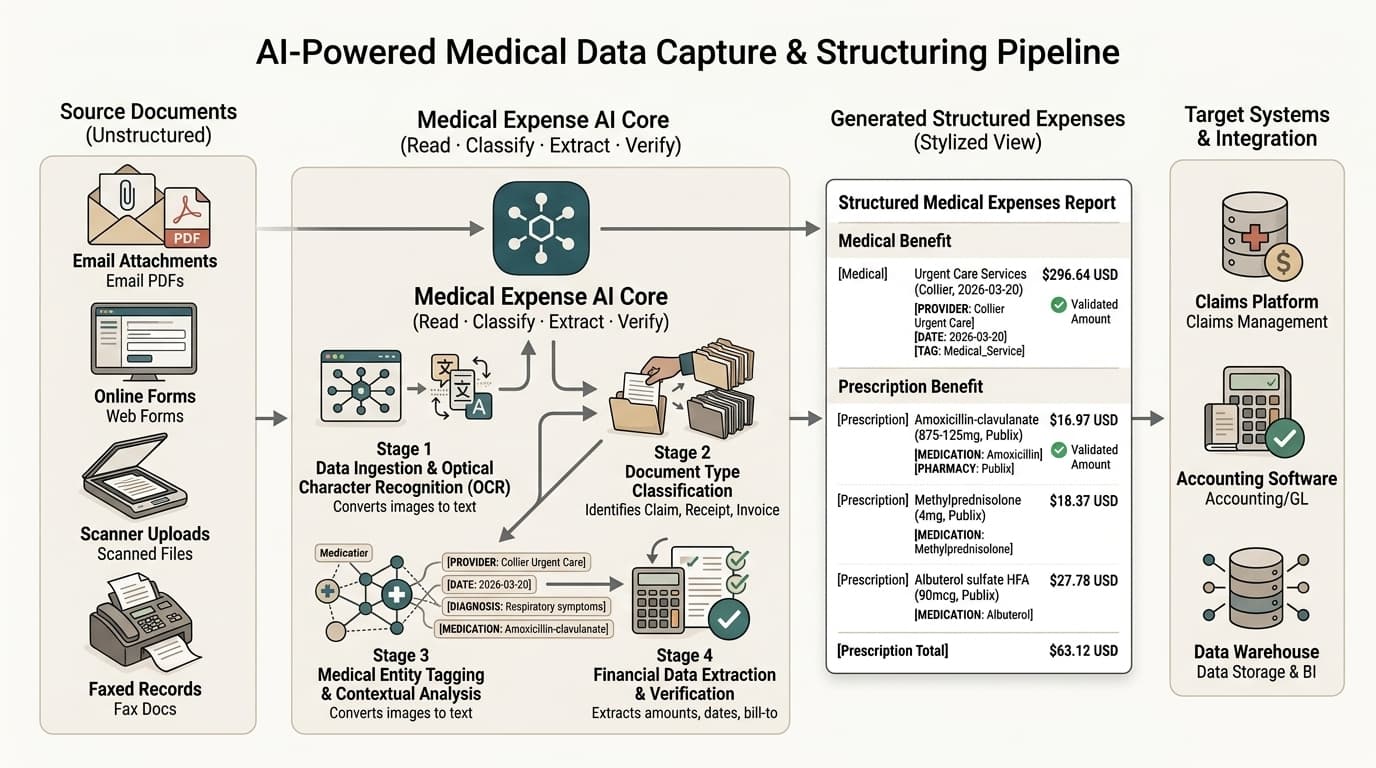
Documents arrive — email, upload, scan, system integration. The pipeline triggers automatically.
Layout-aware extraction reads the document structure (AWS Textract): tables, forms, key-value pairs, paragraphs.
Entity extraction identifies the meaningful fields — vendor, amount, line items, dates, names, identifiers (AWS Comprehend, or domain-specific models).
For specialized domains, domain NLP runs — Comprehend Medical for clinical facts, custom classifiers for insurance / legal / industry patterns.
Extracted data is validated against business rules, summarized where useful, and routed to its destination — accounting system, claims platform, case management, or directly into the Company Memory for queryability.
Where the data needs human eyes, it goes to a review queue with the document and extracted fields side by side. Where it doesn't, it lands silently in your systems and shows up on the next report.
What You Get
- Document ingest pipeline configured for your specific document types
- Cloud AI services (Textract, Comprehend, Comprehend Medical, or open-source equivalents) wired to your data
- Domain-specific tuning — vocabulary, classifiers, validation rules for your industry
- Integration with your downstream systems (accounting, claims, CRM, case management)
- Monitoring, accuracy metrics, exception queue, audit trail
- Per-tenant deployment — your documents, your data, your operational IP, on infrastructure you control
In practice
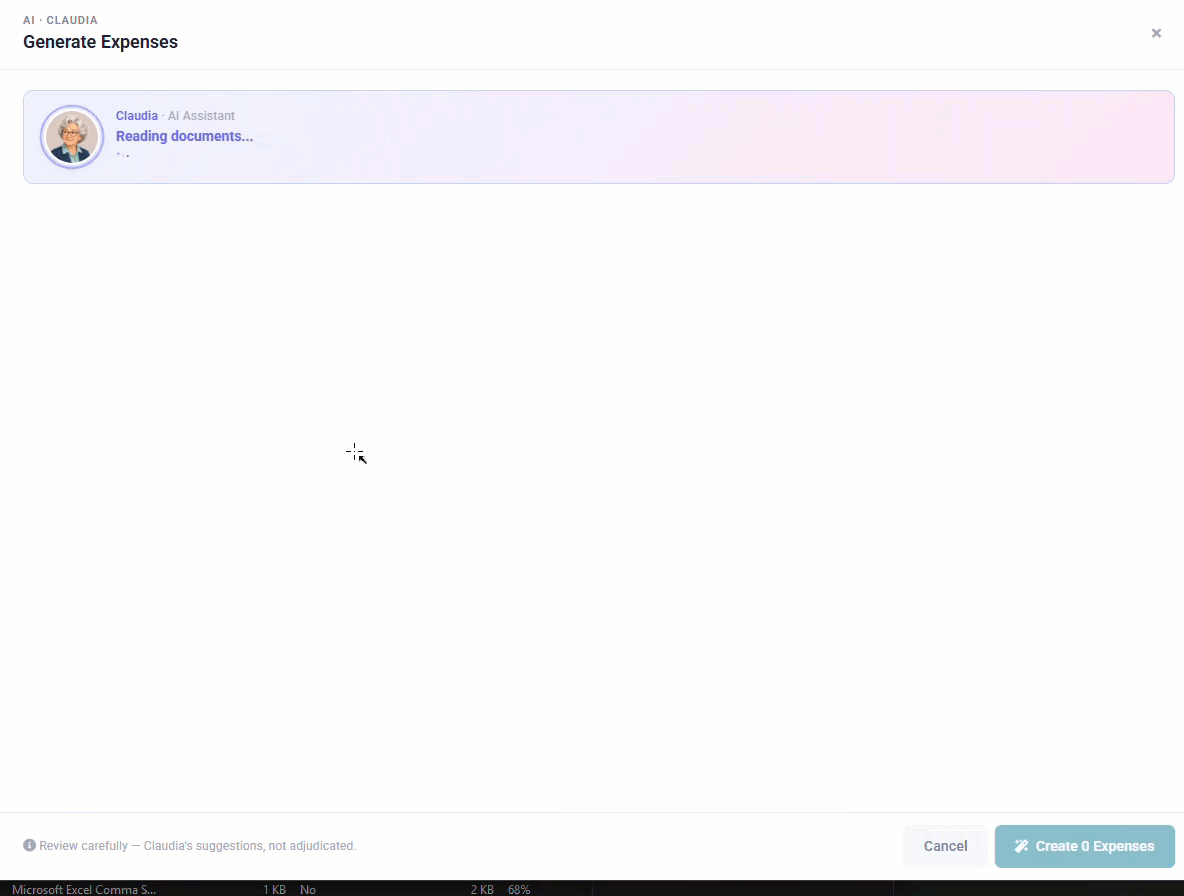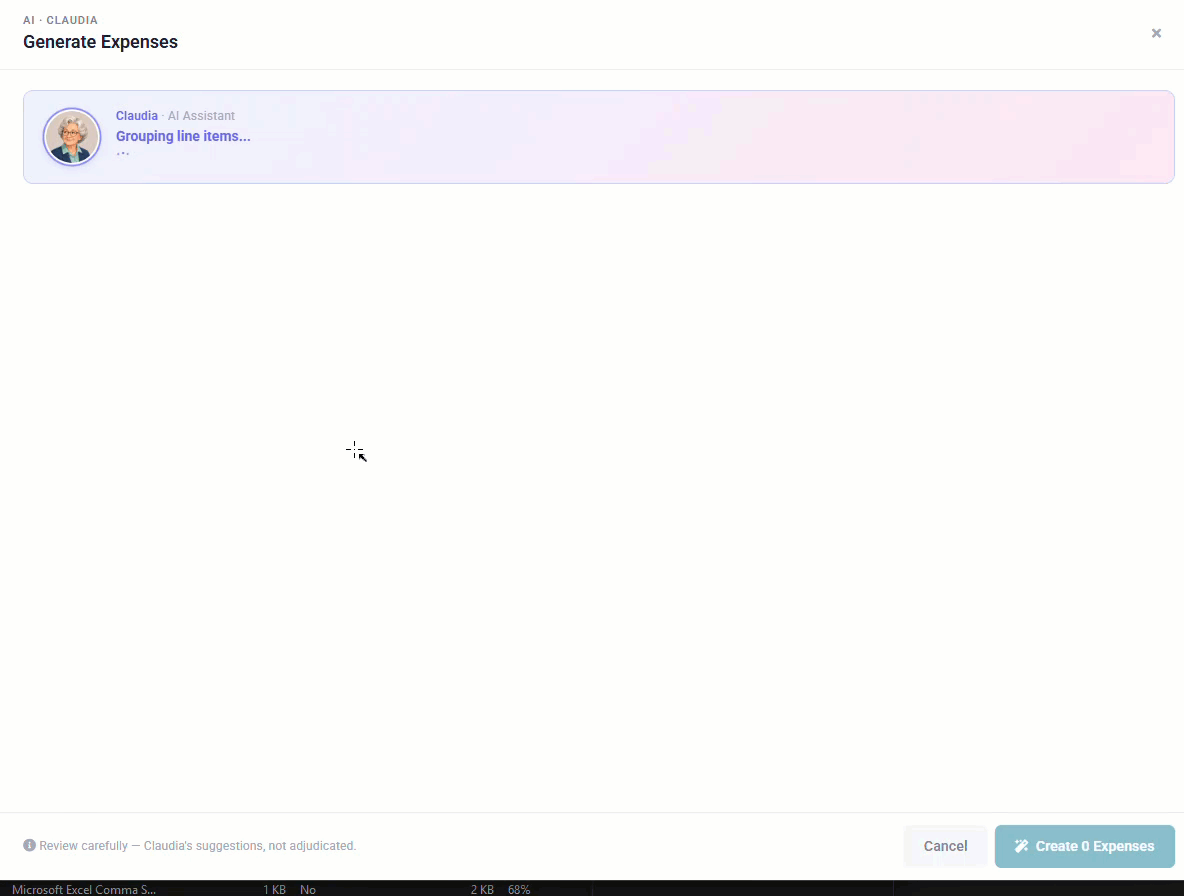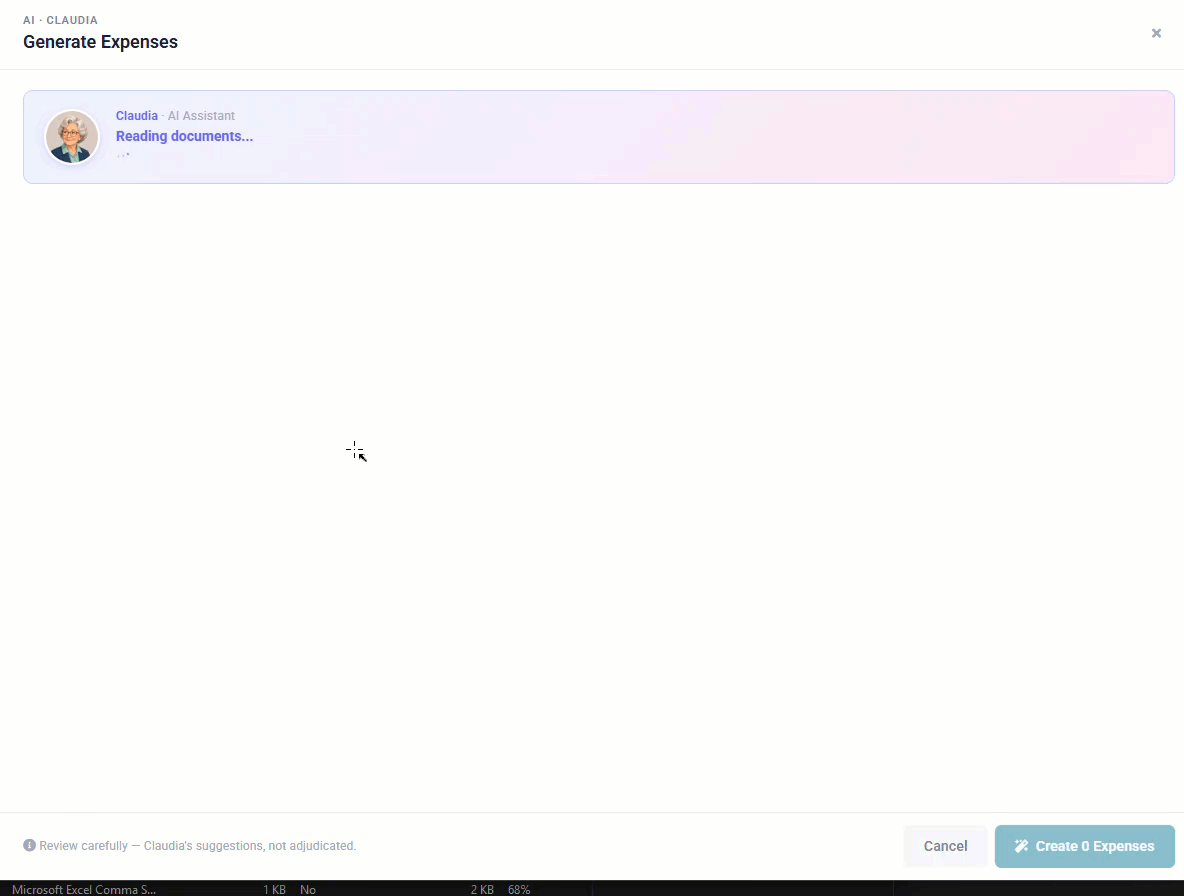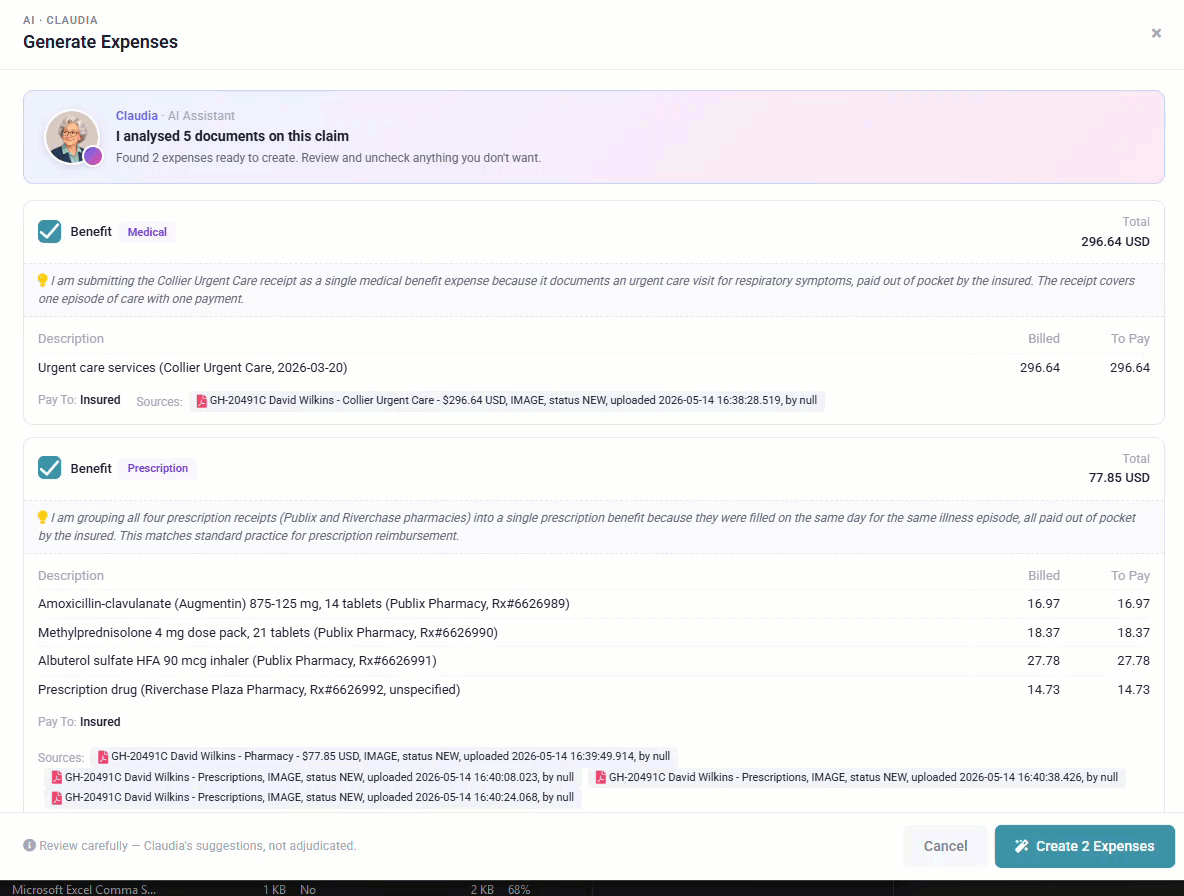
A travel-health-assistance company in our network processes thousands of medical claims documents per month — hospital invoices, treatment reports, prescription records, expense receipts — in multiple languages, in inconsistent layouts. Manual entry is impossible at this volume; legacy keying staff process the same document twice because nothing remembers what came before. The deployed pipeline: Textract reads layout, Comprehend Medical extracts clinical facts, custom classifiers identify cost-containment opportunities. Documents that used to sit in a backlog for weeks are processed within hours. The same Voice-of-Policyholder analysis we produce in twenty minutes runs against this Memory every quarter — patterns surface that were invisible when the documents were dead weight.